3. Detecting facial expressions from videos#
Written by Jin Hyun Cheong and Eshin Jolly
In this tutorial we’ll explore how to use the Detector class to process video files. You can try it out interactively in Google Collab: ![]()
# Uncomment the line below and run this only if you're using Google Collab
# !pip install -q py-feat
3.1 Setting up the Detector#
We’ll begin by creating a new Detector instance just like the previous tutorial and using the defaults:
from feat import Detector
detector = Detector()
detector
feat.detector.Detector(face_model=retinaface, landmark_model=mobilefacenet, au_model=xgb, emotion_model=resmasknet, facepose_model=img2pose, identity_model=facenet)
3.2 Processing videos#
Detecting facial expressions in videos is easy to do using the .detect_video() method. This sample video included in Py-Feat is by Wolfgang Langer from Pexels.
from feat.utils.io import get_test_data_path
import os
test_data_dir = get_test_data_path()
test_video_path = os.path.join(test_data_dir, "WolfgangLanger_Pexels.mp4")
# Show video
from IPython.core.display import Video
Video(test_video_path, embed=False)
Just like .detect_image() we can just pass the path to the video file to .detect_video(). Here we also set skip_frames=24 which tells the detector to process only every 24th frame for the sake of speed:
video_prediction = detector.detect_video(test_video_path, skip_frames=24)
video_prediction.head()
100%|██████████| 20/20 [00:26<00:00, 1.31s/it]
| FaceRectX | FaceRectY | FaceRectWidth | FaceRectHeight | FaceScore | x_0 | x_1 | x_2 | x_3 | x_4 | ... | Identity_506 | Identity_507 | Identity_508 | Identity_509 | Identity_510 | Identity_511 | Identity_512 | input | frame | approx_time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| frame | |||||||||||||||||||||
| 0 | 330.070496 | 41.907721 | 222.043699 | 312.001812 | 0.999788 | 334.606952 | 335.238771 | 339.470413 | 347.475285 | 359.121231 | ... | 0.013548 | 0.025144 | -0.013464 | -0.040379 | 0.001958 | -0.020915 | -0.061315 | /Users/esh/Documents/pypackages/py-feat/feat/t... | 0 | 00:00 |
| 24 | 346.699591 | 43.669070 | 217.335426 | 303.963334 | 0.999697 | 351.959290 | 350.905224 | 353.492541 | 359.888538 | 370.324052 | ... | 0.002161 | 0.027122 | -0.019982 | -0.023538 | 0.055576 | -0.008936 | -0.054490 | /Users/esh/Documents/pypackages/py-feat/feat/t... | 24 | 00:01 |
| 48 | 337.734648 | 41.616590 | 214.032905 | 283.927078 | 0.999782 | 341.442624 | 339.082590 | 339.590616 | 342.465586 | 350.360024 | ... | 0.003118 | 0.010020 | 0.021353 | -0.032861 | 0.008472 | -0.015471 | -0.006659 | /Users/esh/Documents/pypackages/py-feat/feat/t... | 48 | 00:02 |
| 72 | 313.084993 | 60.234503 | 218.443315 | 302.880141 | 0.999261 | 319.038867 | 318.742627 | 322.025177 | 328.489190 | 338.237628 | ... | -0.000539 | 0.008751 | -0.019984 | -0.040222 | 0.052243 | 0.017060 | -0.023802 | /Users/esh/Documents/pypackages/py-feat/feat/t... | 72 | 00:03 |
| 96 | 317.632644 | 85.905809 | 232.158924 | 279.608472 | 0.998265 | 336.531510 | 333.498298 | 332.555208 | 336.279221 | 346.259310 | ... | 0.030832 | 0.037258 | -0.017512 | -0.053172 | 0.010600 | -0.060130 | -0.051994 | /Users/esh/Documents/pypackages/py-feat/feat/t... | 96 | 00:04 |
5 rows × 687 columns
We can see that our 20s long video, recorded at 24 frames-per-second, produces 20 predictions because we set skip_frames=24:
video_prediction.shape
(20, 173)
3.3 Visualizing predictions#
You can also plot the detection results from a video. The frames are not extracted from the video (that will result in thousands of images) so the visualization only shows the detected face without the underlying image.
The video has 24 fps and the actress show sadness around the 0:02, and happiness at 0:14 seconds.
# Frame 48 = ~0:02
# Frame 408 = ~0:14
# Frame numbers are the index so we can use .loc
video_prediction.loc[[48, 408]].plot_detections(faceboxes=False, add_titles=False)
[<Figure size 1500x700 with 3 Axes>, <Figure size 1500x700 with 3 Axes>]
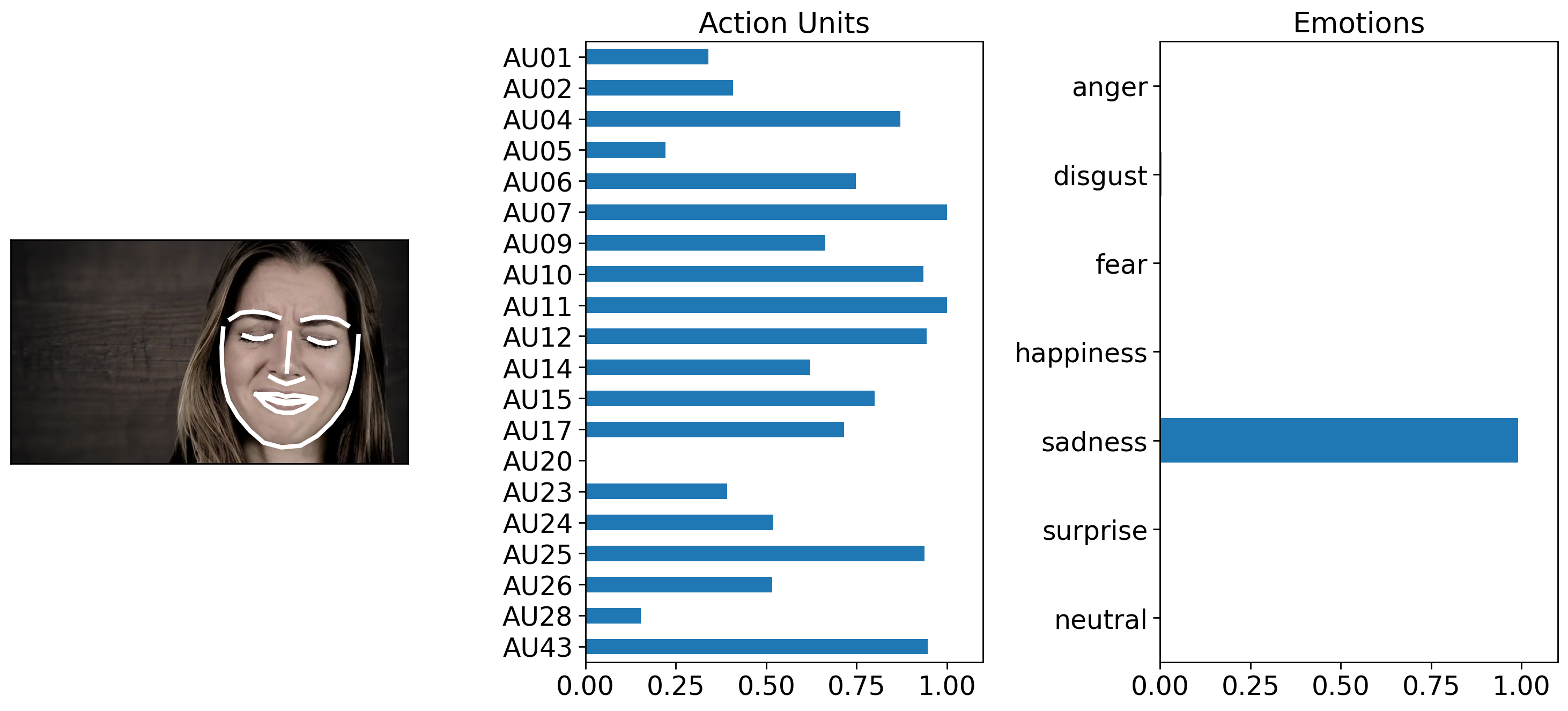
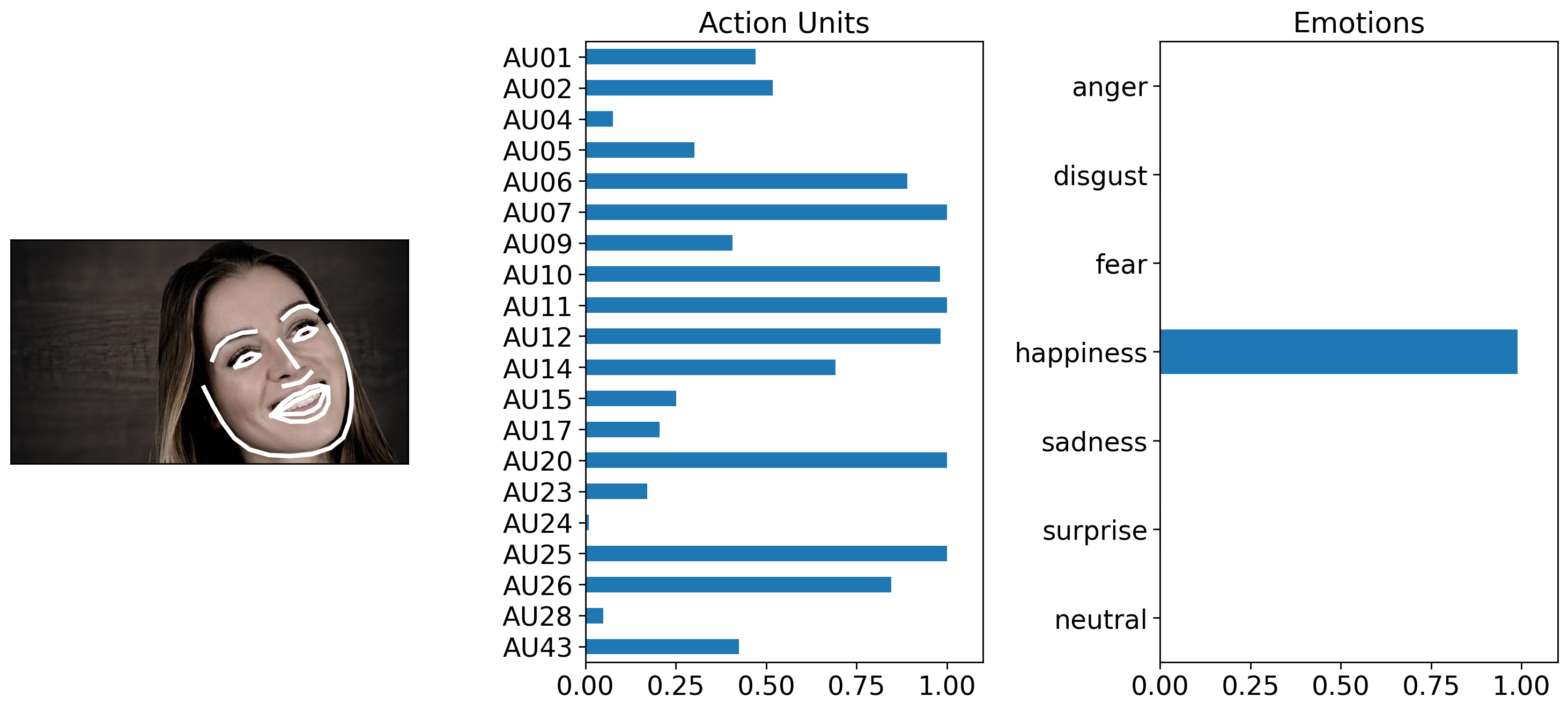
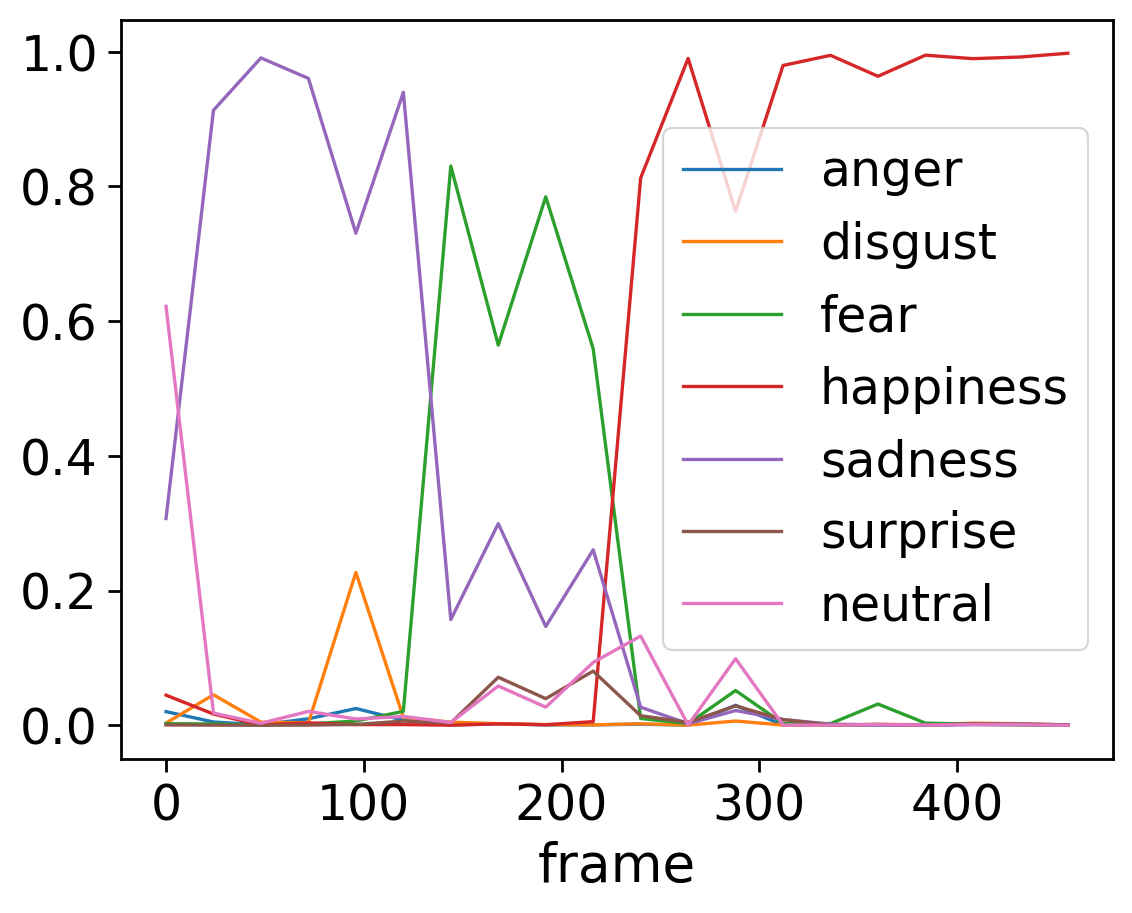
We can also leverage existing pandas plotting functions to show how emotions unfold over time. We can clearly see how her emotions change from sadness to happiness.
axes = video_prediction.emotions.plot()
In situations you want to predict EVERY frame of the video, you can ust leave out the skip_frames argument. Speed of processing may vary depending on the detector you use and the length of the video:
# Run me to get a prediction for EVERY video frame.
# WARNING MAY TAKE A WHILE!
video_prediction = detector.detect_video(test_video_path)